
Infoguana
A cross-project second brain for LLM coding agents — typed-graph notes, hybrid retrieval, and MCP integration.
View on GitHubOverview
Iguanas are ectotherms — they rely on external heat to function. Infoguana (info + iguana) gives LLM agents the same kind of external lifeline: a shared memory that lives outside any single session or repository. It is a typed graph of short notes with hybrid retrieval, designed to feed a coding agent only the slice of memory relevant to the current turn — and to carry hard-won lessons from one project into the next.
Static Rule Files
CLAUDE.md and editor rules load every byte every turn and cap out before they can hold much. They are per-repo, so nothing crosses a project boundary.
Chat-History RAG
Mainstream agent-memory tools are tuned for conversation recall, not curated domain knowledge. Flat top-k lookups, with no locality, typing, or lifecycle.
The Rediscovery Tax
Without shared memory, every new session re-learns gotchas that were already solved months ago — in a different repo, by a different agent.
The thesis: memory should be cross-project by default, typed with a lifecycle, and retrieved by a budgeted graph walk from the current project node — not a flat top-k lookup. Pay the context cost once at session start, then drill into the graph on demand.
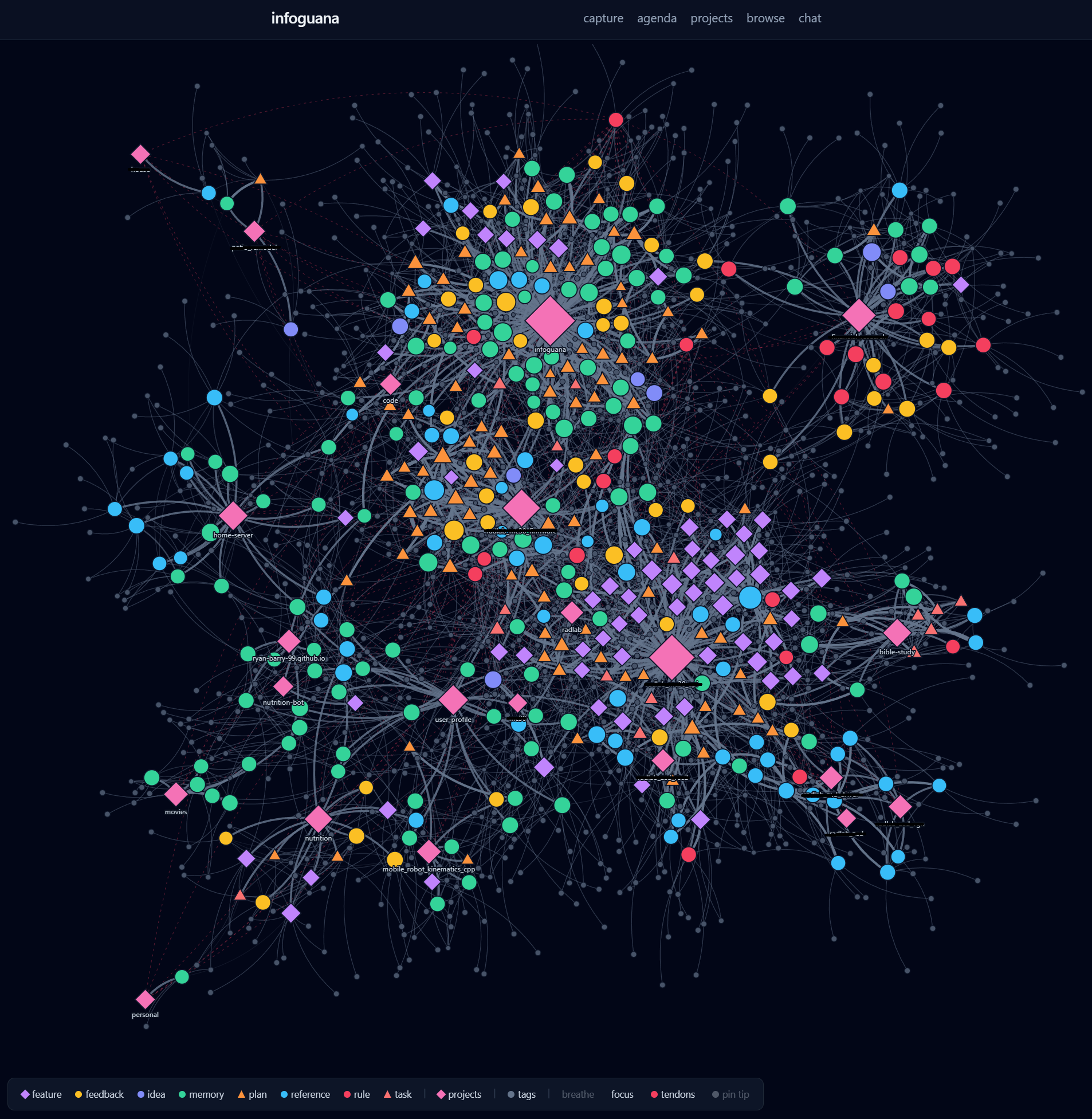
The full corpus as a typed graph — each node is a note (shape and color encode its type), large pink diamonds are projects, and edges are explicit typed links plus IDF-weighted tag co-occurrences.
How It Works
Every note is one of eight types, and the type changes how the note is surfaced. Tags are curated by the agent at write time, and a tag_suggest call ranks existing vocabulary first so tags don't drift into one-off singletons.
Memory
An accumulated, self-contained fact — the actionable substance, captured with the how and why, not just a category label.
Feedback
Sticky guidance the agent should re-read — corrections and confirmed working patterns that shape how it behaves.
Plan / Task
Tracked work with a lifecycle (not started → pending → complete). Pending items pin to the top of every context pack.
Reference
A pointer to substance that lives elsewhere — a dashboard, a design doc, an external resource — loaded on demand.
Hybrid, Budgeted Retrieval
search fuses BM25 lexical scoring (FTS5) and cosine similarity over embeddings (sqlite-vec) into a single ranking. Hits come back as previews — haiku-sized one-to-five-line summaries generated at write time — so an agent can triage twenty results for a few hundred tokens and pull full bodies only for the notes worth quoting. Previews are explicitly for triage, not citation.
Session-Start Context Packing
MCP lets an agent reach infoguana on demand, but it has to remember to ask. To skip that cold start, a SessionStart hook packs the agent's very first turn with a layered, token-budgeted context pack:
- Global-scope rules — cross-project guidance the agent must follow everywhere, pinned with full bodies.
- Project-scope rules — standing constraints tagged to the current repo.
- Project memories, with pending plans and tasks pinned at the top so outstanding work is the first thing the agent sees.
- Everything else fills the remaining budget by IDF-weighted BFS relevance from the project node — and past the budget, it's dropped.
Termination is a token budget, not a hop count, which is what lets retrieval degrade gracefully as the corpus grows. In practice this produces roughly a 15× token reduction versus naively injecting full project history at session start.
The token economics: static rule files cost O(store × turns); top-k RAG costs O(k × turns); infoguana costs O(budget) once at session start, plus O(search) on the explicit calls an agent chooses to make. Breadth, quality, and cost all move the same direction.
Hybrid Search & Filtering
The same hybrid ranking that backs the MCP search tool is exposed through an HTMX web UI, so notes can be captured from a phone or laptop and explored from any browser. A text query combines with faceted filters for type, tag, and status across the entire cross-project corpus, and each hit expands to the full rendered note — body, tags, and typed edges — inline.
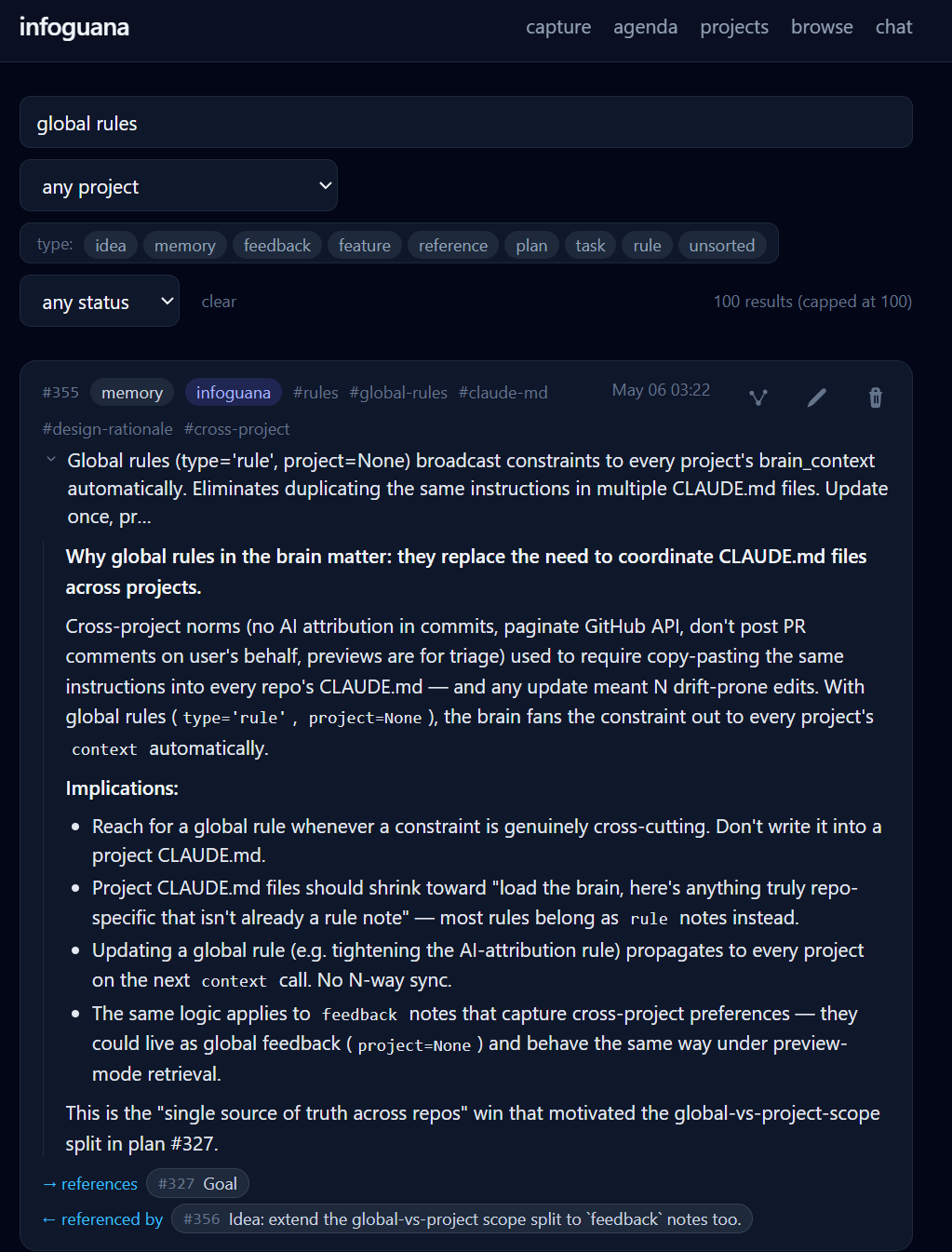
Hybrid search with faceted filtering across every project — each hit expands to the full rendered note, including its tags and typed-edge neighbors.
The Typed Graph
Notes are nodes; the edges between them carry meaning. Six typed-edge relationships — implements, supersedes, references, caused_by, bundled_with, and prerequisite_for — let an agent walk design provenance rather than guess at it.
- Traversal.
traverse(start_id, edge_type)walks the graph for multi-hop questions;search(..., include_edges=True)attaches each hit's neighbors inline, so a plan-or-decision lookup lands in a single call. - Non-destructive updates. Every edit snapshots the prior state and bumps a version;
history(id)returns the diffs, and edges survive parent deletes via tombstones. - Design history as a notebook.
export(start_id)walks the typed-edge graph from a root plan in both directions, pulls in every linked PR, and renders the whole arc — original idea, the plan that implemented it, the decisions it superseded, the bugs it caused, the lessons learned, the PRs that shipped — into one markdown engineering notebook.
Cross-Project Memory
The payoff is what happens across repository boundaries. An agent dropped into any project gets the right few thousand tokens of context on its first turn, can drill into the graph for design intent, and can capture what it learned without inventing new vocabulary — and the next session, possibly in a different repository, sees that knowledge surface again.
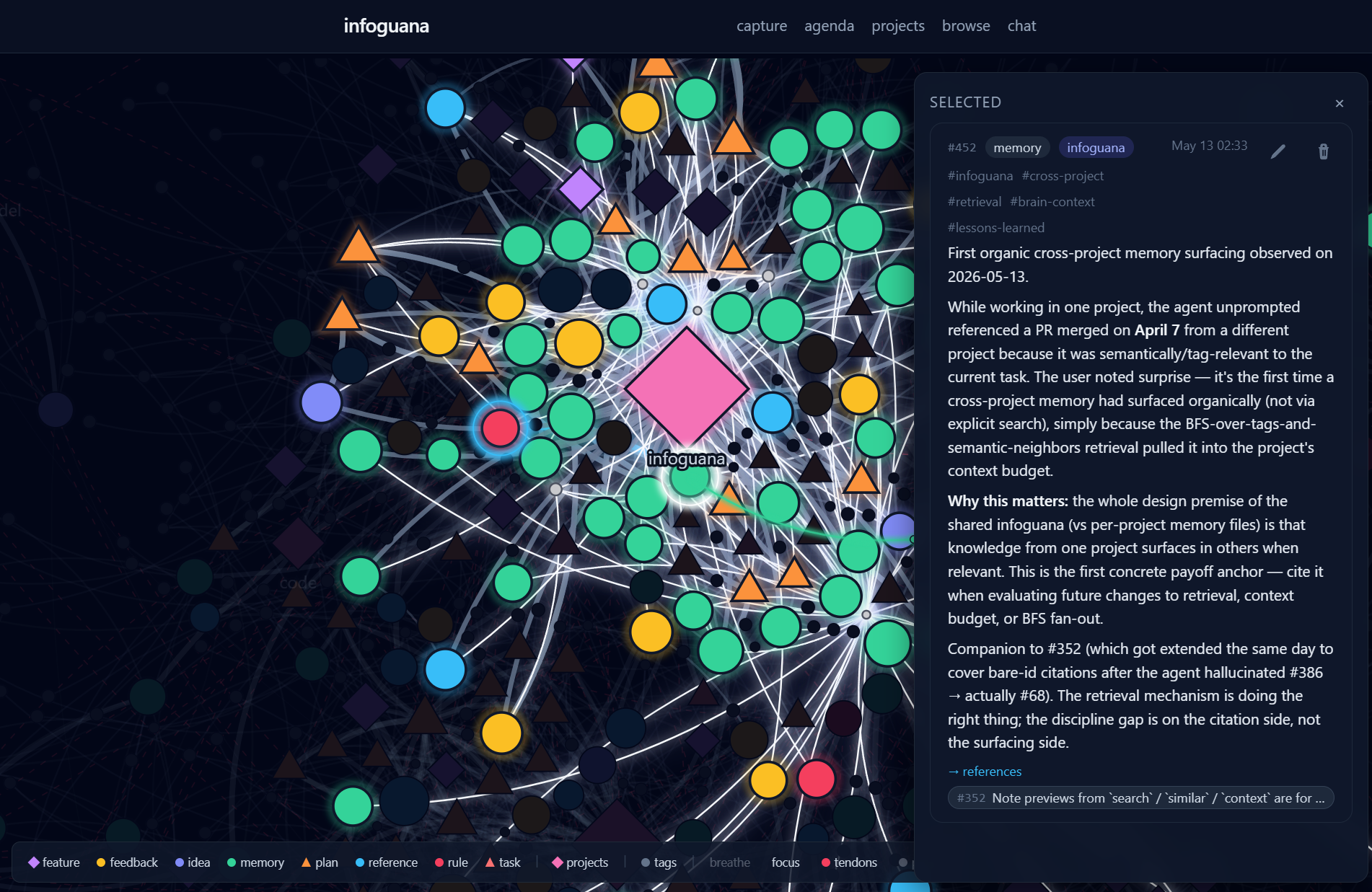
Cross-project recall in action: while working in one repo, the agent surfaced a pull request from a different project — the graph walk over shared tags and semantic neighbors pulled it into the current task's context unprompted.
Why it matters: the whole design premise of a shared brain (versus per-project memory files) is that knowledge from one project surfaces in others when it is relevant — without anyone having to remember it exists.
Architecture & Stack
Infoguana is deliberately a single-file database and a small service — no external search cluster, no managed vector store. The whole system runs from one Docker Compose stack on a home server.
FastAPI
Serves the REST API, the HTMX capture UI, and an MCP Streamable-HTTP endpoint from one async app.
SQLite + vec + FTS5
sqlite-vec holds the embeddings for semantic search; FTS5 provides BM25 lexical scoring. Hybrid retrieval on a single file.
MCP Server
Project-local Claude agents call infoguana over the Model Context Protocol, secured with a per-instance bearer token.
Claude (Haiku)
Runs asynchronous note-type classification and write-time preview generation, off the request path.
MCP Toolset
Agents interact with infoguana entirely through Model Context Protocol tools, grouped by purpose:
Notes
search·similar·recentget·get_many·contextadd·update·deletehistory·tag_suggest
Plans
plansplan_complete
Graph
link·unlinktraverseinfer_edgesexport
Integrations
- GitHub issues & PRs (read)
- Gated issue / comment writes
- Allowlisted filesystem read
Infoguana is open source under the MIT license, with a one-command Docker deploy and a script that wires it straight into Claude Code.
View on GitHub