On Policy Reinforcement Learning for Quadruped Navigation in Unknown Icy Terrain
Graduate research at RIT's Adaptive Human Robot Teaming Lab, advised by Dr. Jamison Heard.
Motivation
Autonomous navigation in unknown and extreme terrains remains an unsolved challenge. Conventional path planning methods rely on depth sensors to detect obstacles, but they fail when the terrain looks traversable but isn't—like icy surfaces that alter friction without any visual indicator.
Invisible Obstacles
Icy terrain cannot be detected by LiDAR or depth cameras. The path appears clear, but friction changes make it impassable.
Adaptive Re-Planning
Robots must learn from experience that a path is blocked and autonomously choose an alternative route in real time.
Novel Approach
Very little research exists on handling invisible obstructions along global paths. This work addresses that gap with reinforcement learning.
Research Question: Can a reinforcement learning policy be developed to enable an agent to adaptively navigate unseen domain shifts in terrain that induce non-systematic errors, such as friction changes or hidden obstacles?
Robotic Platform
The Notspot open-source ROS-based quadruped was selected for its Gazebo simulation interface and preprogrammed trot gait. It was modified with additional sensors for environmental perception.

Original Notspot quadruped

Modified with RealSense D435 and VLP-16 LiDAR
RealSense D435
Front-mounted RGB-D camera providing 480x640 RGB and 720x1280 depth images at 10 Hz.
VLP-16 LiDAR
Top-mounted 3D LiDAR scanner generating point clouds converted to 100x100 occupancy grids via ROS OctoMap.
Joystick Emulator
Custom interface replacing Dualshock 4 controller, enabling autonomous velocity commands via ROS topics.
Simulation Environment

Overhead view of the simple maze environment in Gazebo. Robot starts at top, goal (red) at bottom right.
- Two hallways, each containing a 1° two-sided ramp matching the floor color
- One ramp has normal ground friction, the other has icy friction (μ = 0.05)
- The robot can traverse dry ramps with increased speed but cannot climb icy ramps under any circumstance
- Ramp positions randomly swap with 50% probability at the start of each episode to prevent memorization
- An optimal policy recognizes it is stuck on ice and selects the alternative route
State Representation
At each timestep (0.75 simulated seconds), the robot collects sensor data to form a comprehensive state representation:

RGB Image (480x640)

Depth Image (720x1280)
Occupancy Grid (100x100)
In addition to visual inputs:
- Goal Heuristic — X and Y distance to goal
- IMU Data — Linear acceleration, angular velocity, and goal heading
Proximal Policy Optimization
A custom Actor-Critic PPO implementation coded from scratch in PyTorch within the ROS network.
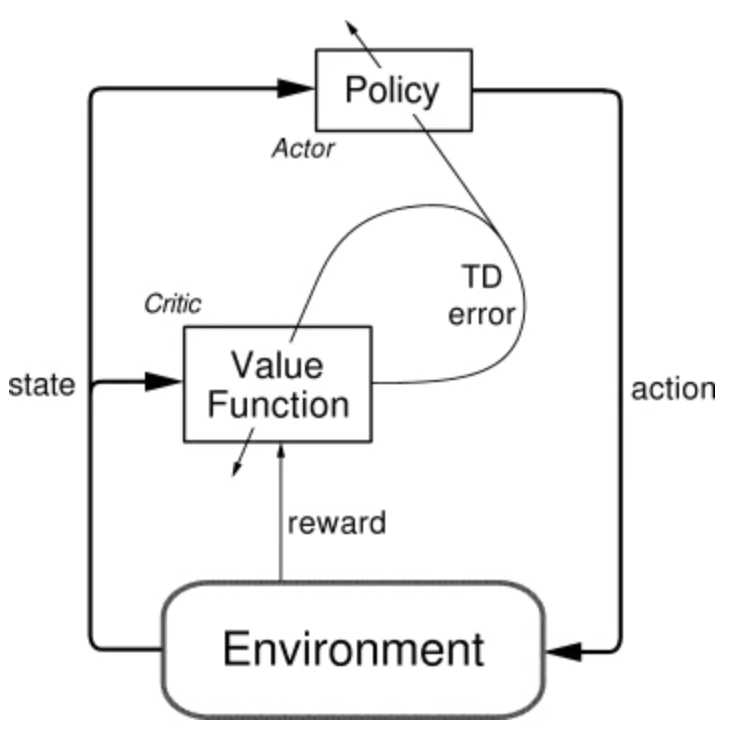
Actor-Critic Architecture: The policy (actor) selects actions, the value function (critic) evaluates them.
Policy Network (Actor)
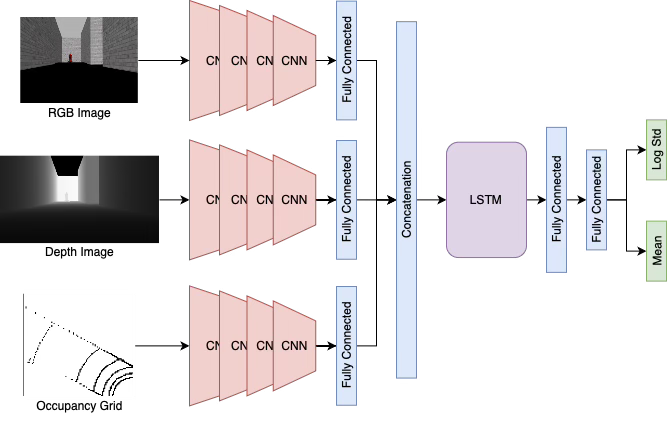
Policy network: CNN branches extract features from RGB, depth, and occupancy grid. Features are concatenated with heuristic and IMU data, processed through LSTM layers, and output mean and log std of velocity commands.
- Three independent CNN branches process each visual input
- Extracted features are concatenated with the heuristic, IMU data, and heading
- LSTM layers provide temporal memory over a trajectory
- Outputs define Gaussian distributions over a continuous velocity action space: [ẋ, ẏ, θ̇]
Value Network (Critic)
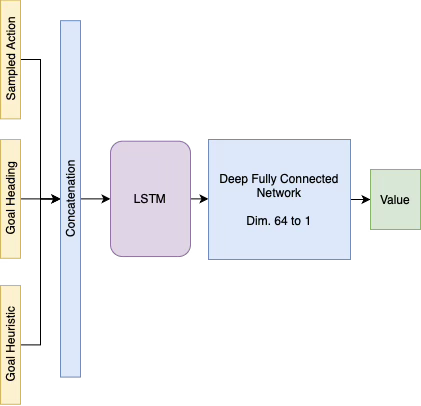
Value network: Takes only the goal heuristic, heading, and sampled action as inputs—visual state information is excluded to avoid unnecessary complexity.
Loss Functions
Policy Loss (Clipped)
Clipped surrogate objective with ε = 0.2 prevents large policy updates and stabilizes training.
Value Loss (MSE)
Mean squared error between predicted values and discounted rewards.
Entropy Bonus
Weighted by c2 = 0.1 to encourage exploration and prevent premature convergence.
GAE (λ = 1)
Generalized Advantage Estimation fully accounts for future rewards along each trajectory.
Training Protocol
- Each trajectory comprises 250 steps, providing sufficient temporal depth for the LSTM
- States, actions, rewards, log probabilities, and values stored in a custom experience buffer
- Policy and value networks updated via backpropagation at the end of each trajectory or episode
- LSTM hidden layers reset at the start of each trajectory
Terminal States
Episodes end when the robot reaches the goal or has not moved for 20 consecutive steps (e.g., falls over, velocity too low, or stuck at a wall).

Example terminal state: robot has fallen over on icy terrain
Reward Function Design
Three reward functions were evaluated to understand their impact on policy convergence:
Reward 1
- +1 Agent reaches the goal
- −2 Agent remains stationary
- 0 Otherwise
Encourage exploration without creating a greedy agent.
Reward 2
- +1 Decreases distance to goal
- −2 Fails to decrease distance
Reward the robot for adhering to a global planner. As distance to goal approaches 0, the overall reward structure remains the same.
Reward 3
- +1 Decreases minimum distance to goal
- −2 Increases distance to goal
- 0 Otherwise
Same global planner rationale as Reward 2, but only rewards new minimum distances, allowing lateral movement without penalty.
Results
Sparse Reward (Reward 1) — Complex Maze
No significant learning progress. The robot never reached the goal on its own. The agent struggled to discern the optimal strategy of navigating away from the maze's center. Sparse rewards provided insufficient signal for the agent to learn meaningful behaviors. A leading hypothesis is that PPO may need to be integrated as a local planner alongside a global planner for complex environments. The experiment was transitioned to the simpler maze and switched to dense reward functions.
Dense Reward 2 — 1,000,000 Steps
The policy failed to converge, mainly due to the value network's inability to learn the reward function, resulting in substantial losses. The agent struggled to make progress towards the goal, as evidenced by consistently negative average rewards. However, compared retrospectively with Reward 3, the agent showed a higher propensity to move towards the goal. The policy plateaus and fails to fully converge on a strategy that consistently approaches the goal.
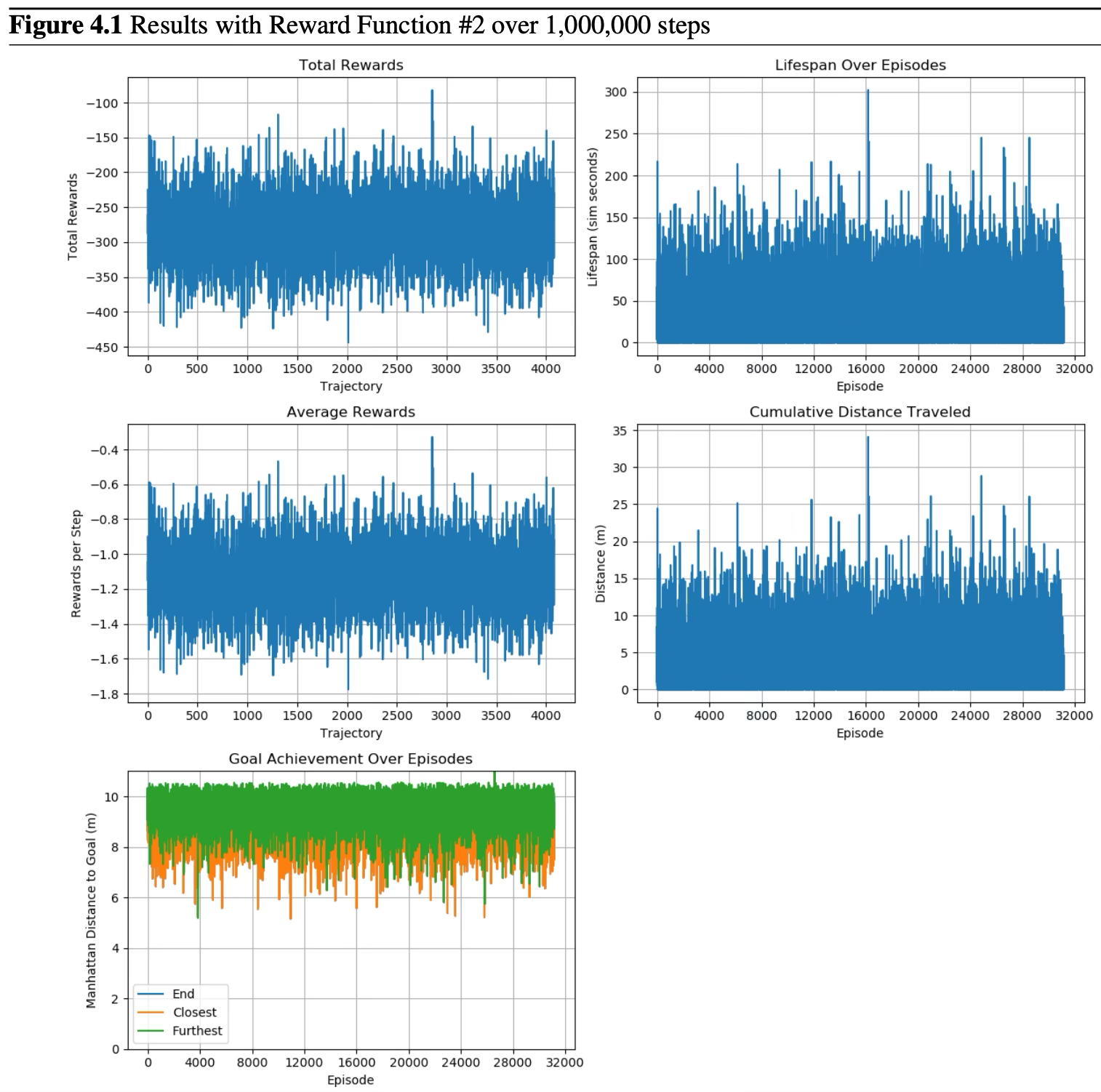
Results with Reward Function #2 over 1,000,000 steps. Top left: total rewards. Top right: lifespan over episodes. Middle left: average rewards per step. Middle right: cumulative distance traveled. Bottom: goal achievement showing end, closest, and furthest distances.
Dense Reward 3 — 1,000,000 Steps
This reward function only rewards the agent for forward movement that decreases its minimum distance to the goal. Additionally, the value network was adjusted to use tanh activation functions instead of ReLU to account for negative numbers in the heading and y component of the heuristic. Despite these changes, similar substantial losses were observed between the value and policy networks. The agent maintains a steady exploration pattern but fails to reliably converge on an optimal goal-reaching policy.
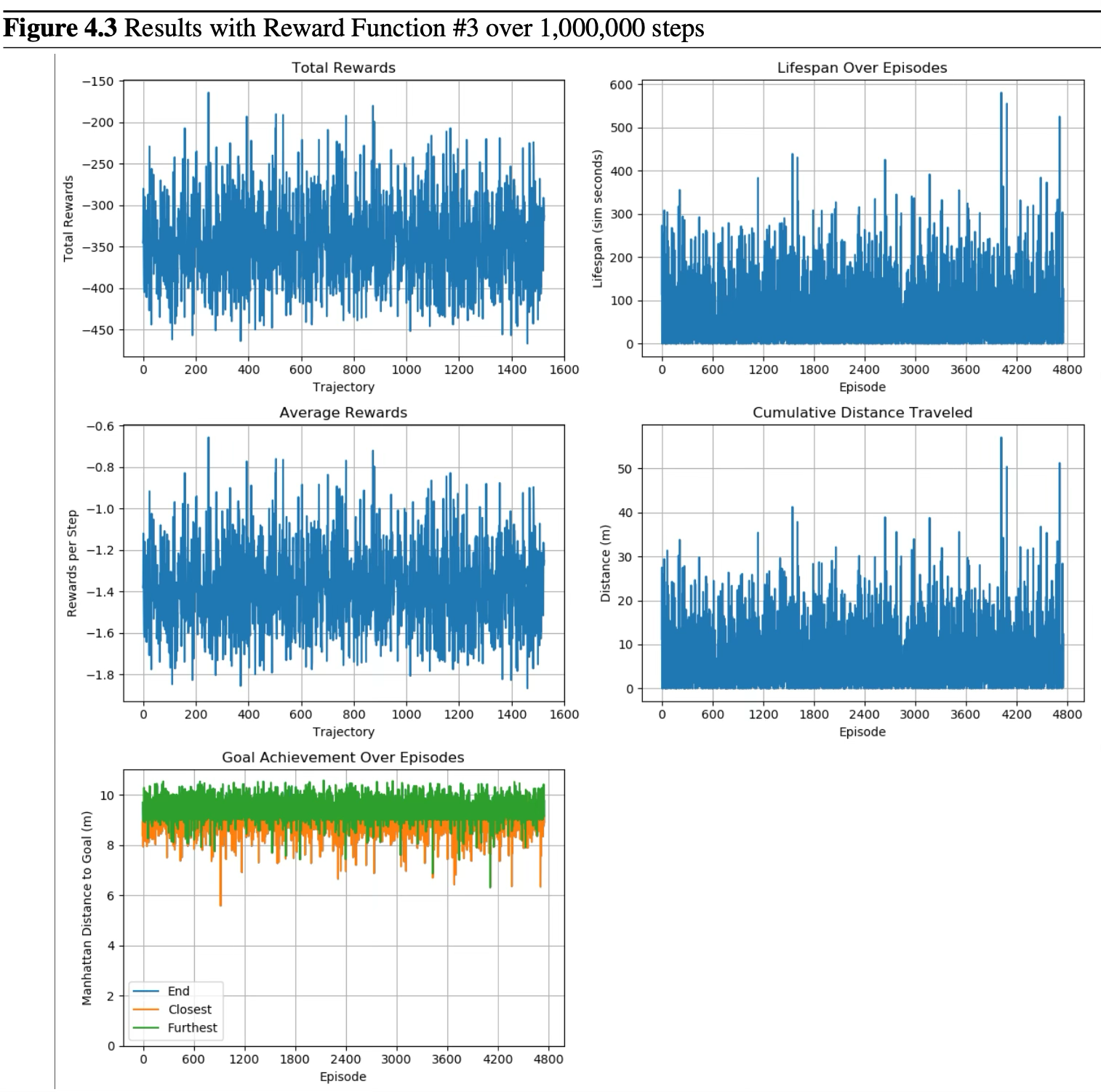
Results with Reward Function #3 over 1,000,000 steps. The agent shows increased lifespan and distance traveled compared to Reward 2, but goal achievement remains inconsistent.
Key Analysis: The primary hypothesis for the agent's navigational challenges lies in treating the value function as a regression problem rather than a classification problem. Since the reward functions are piecewise and deterministic across a few cases, the value function should reflect this by outputting a probability distribution over the possible reward states. With this adjustment, the agent should better learn to navigate towards the goal with a clearer understanding of the value of a state-action pair.
Future Work
Phased Training with Randomized Goals
Pre-train the policy to approach a randomized goal position in a simple open environment before adding maze complexity. Inspired by the RoboschoolHumanoidFlagrun approach from OpenAI's PPO paper, building foundational navigation skills before introducing domain shifts.
Vision Language Model (VLM) Policy Network
Replace CNN feature extractors with a VLM to generate rich textual descriptions of the visual state. Leverage large pre-trained models for more detailed contextual information than raw pixel features. Maintain a buffer of recent state text embeddings to capture temporal relationships.
Transformer-Based Architecture
Replace or augment the LSTM with a transformer model for synthesizing state representations into action spaces, potentially improving long-range temporal reasoning.
Value Network Reformulation
Restructure the value network to treat reward prediction as a classification problem, outputting a probability distribution over discrete reward states instead of a continuous regression estimate.